# Import all packages
# General utilities:
import os
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import warnings
# Stats
import pymc as pm
import arviz as az
import bambi as bmb
from scipy.special import logit
# Custom packages:
from stabst.MarkovDecisionProcess import MDP
from stabst.TaskConfig import LimitedEnergyTask
from stabst.utils import avg_reduce_mdp, abstract2ground_value
# Set random seed for reproducibility:
np.random.seed(42)
warnings.filterwarnings("ignore")
n_samples = 1000
n_warmup = 1000
n_chains = 4
# Choice behaviour model with preferences and decision values:
def preference_model(
y: np.array,
decision_values: np.array,
pref_regressors: pd.DataFrame,
subject_index: np.array,
subject_labels: np.array
):
'''
Parameters
----------
y : np.array [N samples, ]
Observed binary data (1, 0...)
decision_values : np.array [N samples, ]
Decision values to regress onto the observed data
pref_regressors : np.array [N samples, M regressors]
Regressor to fit participants preference for. We can have M regressors
subject_index : np.array [N samples, ]
Index of the subject associated with each observation
subject_labels : np.array [N subjects, ]
Single identifier of each subject
coords : dict
"subject": subj_labels,
"coef": ["intercept", "slope"],
The subject maps the data to each subject, the coef are for the coefficients
b_prior_mean : Optional[float], optional
Prior mean of each beta parameters, by default 0
b_prior_sigma : Optional[float], optional
Prior variance of the population level distribution of the beta, by default 2
s_prior_sigma : Optional[float], optional
Prior between subjects variance, by default 2
n_drawss : Optional[int], optional
Number of draws for the posterior, by default 1000
n_tuning_draws : Optional[int], optional
Number of tuning draws, by default 1000
Returns
-------
tuple[pm.Model, arviz.InferenceData]
pm.model : pymc model object
idata : arviz inference data
"""
'''
# Get dimensions:
n_obs = y.shape[0]
n_groups = subject_labels.shape[0]
n_pref = pref_regressors.shape[1]
# Create intercept:
intercept = np.ones(n_obs)
# Set coordinates:
coords = {
"subject": subject_labels,
"coef_intercept": ["B_intercept"],
"coef_planning": ["B_plan"],
"coef_pref": ["B_" + col for col in pref_regressors.columns],
"coef_interaction": ["slope"],
}
# Model:
with pm.Model(coords=coords) as planning_preferences_interaction_model:
# Data:
y_obs = pm.Data("y_obs", y)
intercept = pm.Data("intercept", intercept)
planning = pm.Data("planning", decision_values)
preferences = pm.Data("preferences", pref_regressors)
subj_idx = pm.Data("subj_idx", subject_index.astype("int32"))
# Hyperpriors:
# Intercept term
beta_intercept = pm.Normal("beta_intercept", mu=0, sigma=2, dims="coef_intercept")
sigma_intercept = pm.HalfNormal("sigma_intercept", sigma=2, dims="coef_intercept")
# Planning term:
beta_planning = pm.Normal("beta_planning", mu=0, sigma=2, dims="coef_planning")
sigma_planning = pm.HalfNormal("sigma_planning", sigma=2, dims="coef_planning")
# Preference terms:
beta_pref = pm.Normal("beta_pref", mu=0, sigma=2, dims="coef_pref")
sigma_pref = pm.HalfNormal("sigma_pref", sigma=2, dims="coef_pref")
# Interaction term:
beta_interaction = pm.Normal("beta_interaction", mu=0, sigma=2, dims="coef_interaction")
sigma_interaction = pm.HalfNormal("sigma_interaction", sigma=2, dims="coef_interaction")
# Offset parameters:
z_intercept = pm.Normal("z_intercept", 0, 1, dims=("subject", "coef_intercept"))
z_planning = pm.Normal("z_planning", 0, 1, dims=("subject", "coef_planning"))
z_biases = pm.Normal("z_biases", 0, 1, dims=("subject", "coef_pref"))
z_interaction = pm.Normal("z_interaction", 0, 1, dims=("subject", "coef_interaction"))
# Centered parameters:
beta_intercept_sub = pm.Deterministic("beta_intercept_sub", beta_intercept + z_intercept * sigma_intercept,
dims=("subject", "coef_intercept"))
beta_planning_sub = pm.Deterministic("beta_planning_sub", beta_planning + z_planning * sigma_planning,
dims=("subject", "coef_planning"))
beta_pref_sub = pm.Deterministic("beta_pref_sub", beta_pref + z_biases * sigma_pref,
dims=("subject", "coef_pref"))
beta_interaction_sub = pm.Deterministic("beta_interaction_sub", beta_interaction + z_interaction * sigma_interaction,
dims=("subject", "coef_interaction"))
# Estimate the score of the bias (i.e. weighted sum of each of the biases regressors):
preference = pm.Deterministic('preference', (beta_pref_sub[subj_idx] * preferences).sum(axis=-1))
# Convert the bias back onto probability space:
pi_prior = pm.Deterministic("pi_prior", pm.math.sigmoid(preference))
# Compute the entropy:
entropy = pm.Deterministic("entropy", -pi_prior * pm.math.log(pi_prior) - (1-pi_prior) * pm.math.log(1 - pi_prior))
# Eta parameter is the weighted sum of the intercept, the bias, the planning values and
# the interaction between the entropy of the bias and the planning
eta = (
beta_intercept_sub[subj_idx, 0] * intercept
+ preference
+ beta_planning_sub[subj_idx, 0] * planning
+ beta_interaction_sub[subj_idx, 0] * (entropy * planning)
)
# Expected values:
p = pm.Deterministic("p", pm.math.sigmoid(eta))
# Likelihood
pm.Bernoulli("y", p=p, observed=y_obs)
# Sampling:
idata = pm.sample(
draws=n_samples,
tune=n_warmup,
chains=n_chains,
target_accept=0.85,
idata_kwargs={"log_likelihood": True},
)
return idataTo investigate the relationship between task structures and participants preferences, we fitted a model in which we fitted a latent preference score computed as the weighted sum of regressors associated with each factors of our task (offers, energy, current and future costs) where the weight associated with each are estimated from participants data. In addition, the model comprised a fixed effect for the decision values derived from reinforcement learning (RL) backward induction method to represent the behaviour of an optimal planner, as well as an interaction between the decision values and the entropy of the preferences scores, to investigate whether participants reliance on planning depends on the strength of their preferences.
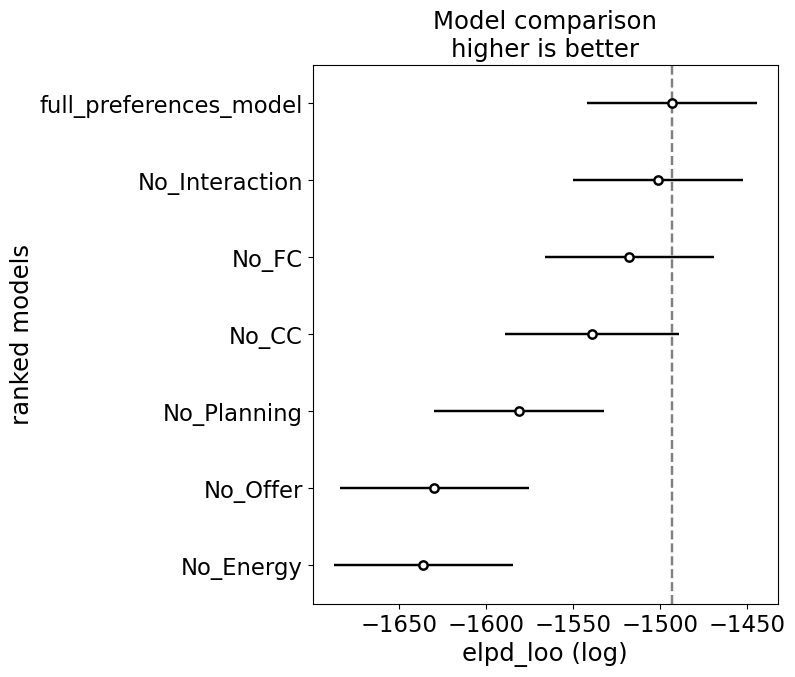
We’ve observed that this model fits the data better than the original hybrid model from @ott2022forward. In addition, we compared the full model described above to reduced models in which we in turn removed the decision values, factors (offers, energy, current and future costs) from the computation of the preferences, and the interaction between preferences and the decision values to test the fit of our model:
In [1]:
Preparing the data:
We apply the exact same preprocessing as in the manuscript notebook
In [2]:
# Download the data if needed:
if not os.path.exists('../data/raw_data/all_participants_data.csv'):
if not os.path.exists('../data/raw_data'):
os.makedirs('../data/raw_data')
url = 'https://raw.githubusercontent.com/fmott/context_dependent_planning/4d239b721749adabb8fe8f1d8ac2d1ecdeba17cf/data/behaviour/data_all_participants_20220215120148.csv'
os.system(f'wget {url} -O ../data/raw_data/all_participants_data.csv')
if not os.path.exists('../data/raw_data/all_participants_age_gender.csv'):
if not os.path.exists('../data/raw_data'):
os.makedirs('../data/raw_data')
url = 'https://raw.githubusercontent.com/fmott/context_dependent_planning/4d239b721749adabb8fe8f1d8ac2d1ecdeba17cf/data/behaviour/age_gender.csv'
os.system(f'wget {url} -O ../data/raw_data/all_participants_age_gender.csv')
# Load the data:
beh_data = pd.read_csv('../data/raw_data/all_participants_data.csv')
demographic_data = pd.read_csv('../data/raw_data/all_participants_age_gender.csv', sep=";")
# Extract demographic information:
n_participants = demographic_data.shape[0]
n_female = demographic_data['gender (m = 1, f = 2)'].value_counts()[2]
mean_age = demographic_data['age'].mean()
std_age = demographic_data['age'].std()
# ===================================================================
# Data preprocessing:
# Remove nans:
beh_data = beh_data.dropna()
# Remove timeout:
beh_data = beh_data[beh_data["timeout"] == 0]
# Flip responses: 1 = accept:
beh_data["response"] = (beh_data["response"] == 0).astype(int)
# Make trial 1 based
beh_data["trial"] = beh_data["trial"] + 1
# Generate future cost based on the transitions:
transitions_costs = {
0: [1, 1],
1: [2, 1],
2: [1, 2],
3: [2, 2]
}
beh_data["fc"] = [transitions_costs[row["transition"]][1] for _, row in beh_data.iterrows()]
# ===================================================================
# Prepare the decision values:
# Task MDP:
# Create the task and its parameters (transition probability, reward...):
task = LimitedEnergyTask(O=[1, 2, 3, 4], p_offer=[1/4] * 4)
task.build()
# Create full MDP and compute solution for later reference:
gamma = 1
task_mdp = MDP(task.states, task.tp, task.r, gamma, s2i=task.s2i)
V_full, Q_full = task_mdp.backward_induction()
# Add decision values to the data frame:
dv = Q_full[:, 1] - Q_full[:, 0]
# Loop through each trial to set DV:
dv_trials = []
for trial_i, trial in beh_data.iterrows():
e, o, cc, t = trial.energy, trial.reward, trial.energy_cost, trial.trial
fc = transitions_costs[trial.transition][1]
dv_trials.append(dv[task.s2i[(e, o, cc, fc, t)]])
beh_data['dv'] = dv_trials
# Compute offer specific decision value regressors:
beh_data['dv_23'] = beh_data['dv'].to_numpy() * (beh_data['is_2'].to_numpy() + beh_data['is_3'].to_numpy())
beh_data['dv_14'] = beh_data['dv'].to_numpy() * (beh_data['is_1'].to_numpy() + beh_data['is_4'].to_numpy())
# ===================================================================
# Preparing regressors:
# Categorical offer regressor for high and low offer
beh_data['is_12'] = beh_data['is_1'].to_numpy() + beh_data['is_2'].to_numpy()
beh_data['is_34'] = beh_data['is_3'].to_numpy() + beh_data['is_4'].to_numpy()
# Continuous regressor for high and low offer:
beh_data['high_vs_low'] = beh_data['is_34'] - beh_data['is_12']
# Categorical costs regressor
beh_data['is_lc'] = (beh_data['energy_cost'] == 1).astype(int).to_numpy()
beh_data['is_hc'] = (beh_data['energy_cost'] == 2).astype(int).to_numpy()
# Categorical future costs regressor
beh_data['is_lfc'] = (beh_data['fc'] == 1).astype(int).to_numpy()
beh_data['is_hfc'] = (beh_data['fc'] == 2).astype(int).to_numpy()
# Categorical transition regressor
beh_data['is_trans1'] = (beh_data['transition'] == 0).to_numpy()
beh_data['is_trans2'] = (beh_data['transition'] == 1).to_numpy()
beh_data['is_trans3'] = (beh_data['transition'] == 2).to_numpy()
beh_data['is_trans4'] = (beh_data['transition'] == 3).to_numpy()
# Categorical energy regressor:
beh_data['e_is_0'] = (beh_data['energy'] == 0).to_numpy()
beh_data['e_is_1'] = (beh_data['energy'] == 1).to_numpy()
beh_data['e_is_2'] = (beh_data['energy'] == 2).to_numpy()
beh_data['e_is_3'] = (beh_data['energy'] == 3).to_numpy()
beh_data['e_is_4'] = (beh_data['energy'] == 4).to_numpy()
beh_data['e_is_5'] = (beh_data['energy'] == 5).to_numpy()
beh_data['e_is_6'] = (beh_data['energy'] == 6).to_numpy()
# Random effects
subj_idx_raw, subj_labels = pd.factorize(beh_data["vpn"])Fitting the full model
First, we fit the full model, which will then be compared to reduced models:
In [3]:
# Fitting the models:
traces = {}
# ===================================================================
# Preference model:
if os.path.exists("../data/bids/limited_energy/derivatives/models/preferences_model-v2.nc"):
idata = az.from_netcdf("../data/bids/limited_energy/derivatives/models/preferences_model-v2.nc")
traces['full_preferences_model'] = idata
else:
preference_columns = [
'is_1', 'is_2', 'is_3', 'is_4',
'is_lc', 'is_hc',
'is_lfc', 'is_lhc',
'e_is_0', 'e_is_1', 'e_is_2', 'e_is_3', 'e_is_4', 'e_is_5', 'e_is_6'
]
idata = preference_model(beh_data['response'], # Subjects responses
np.squeeze(beh_data[['dv']].to_numpy()), # Optimal decision values
beh_data[preference_columns], # Preferences regressors
subj_idx_raw, subj_labels)
# Add the idata to the rest:
traces['full_preferences_model'] = idata
# Save the trace to file:
if not os.path.exists("../data/bids/limited_energy/derivatives/models/"):
os.makedirs("../data/bids/limited_energy/derivatives/models/")
az.to_netcdf(idata, "../data/bids/limited_energy/derivatives/models/preferences_model-v2.nc")Compute models removing each factors from the preferences:
Then, we compute the same model, but removing each factors from the task when computing the preferences:
In [4]:
# ===================================================================
# Model without offer related preferences:
if os.path.exists("../data/bids/limited_energy/derivatives/models/preferences_model_no_offer_trace.nc"):
idata = az.from_netcdf("../data/bids/limited_energy/derivatives/models/preferences_model_no_offer_trace.nc")
traces['No_Offer'] = idata
else:
preference_columns = [
'is_lc', 'is_hc',
'is_lfc', 'is_hfc',
'e_is_0', 'e_is_1', 'e_is_2', 'e_is_3', 'e_is_4', 'e_is_5', 'e_is_6'
]
idata = preference_model(beh_data['response'], # Subjects responses
np.squeeze(beh_data[['dv']].to_numpy()), # Optimal decision values
beh_data[preference_columns], # Preferences regressors
subj_idx_raw, subj_labels)
# Add the idata to the rest:
traces['No_Offer'] = idata
# Save the trace to file:
az.to_netcdf(traces['No_Offer'], "../data/bids/limited_energy/derivatives/models/preferences_model_no_offer_trace.nc")
# ===================================================================
# Model without current costs related preferences:
if os.path.exists("../data/bids/limited_energy/derivatives/models/preferences_model_no_costs_trace.nc"):
idata = az.from_netcdf("../data/bids/limited_energy/derivatives/models/preferences_model_no_costs_trace.nc")
traces['No_CC'] = idata
else:
# Fit the model without the costs related preferences:
preference_columns = [
'is_1', 'is_2', 'is_3', 'is_4',
'is_lfc', 'is_hfc',
'e_is_0', 'e_is_1', 'e_is_2', 'e_is_3', 'e_is_4', 'e_is_5', 'e_is_6'
]
idata = preference_model(beh_data['response'], # Subjects responses
np.squeeze(beh_data[['dv']].to_numpy()), # Optimal decision values
beh_data[preference_columns], # Preferences regressors
subj_idx_raw, subj_labels)
# Add the idata to the rest:
traces['No_CC'] = idata
# Save the trace to file:
az.to_netcdf(traces['No_CC'], "../data/bids/limited_energy/derivatives/models/preferences_model_no_costs_trace.nc")
# ===================================================================
# Model without future costs related preferences:
if os.path.exists("../data/bids/limited_energy/derivatives/models/preferences_model_no_future_costs_trace.nc"):
idata = az.from_netcdf("../data/bids/limited_energy/derivatives/models/preferences_model_no_future_costs_trace.nc")
traces['No_FC'] = idata
else:
# Fit the model without the future costs related preferences:
preference_columns = [
'is_1', 'is_2', 'is_3', 'is_4',
'is_lc', 'is_hc',
'e_is_0', 'e_is_1', 'e_is_2', 'e_is_3', 'e_is_4', 'e_is_5', 'e_is_6'
]
idata = preference_model(beh_data['response'], # Subjects responses
np.squeeze(beh_data[['dv']].to_numpy()), # Optimal decision values
beh_data[preference_columns], # Preferences regressors
subj_idx_raw, subj_labels)
# Add the idata to the rest:
traces['No_FC'] = idata
# Save the trace to file:
az.to_netcdf(traces['No_FC'], "../data/bids/limited_energy/derivatives/models/preferences_model_no_future_costs_trace.nc")
# ===================================================================
# Model without energy related preferences:
if os.path.exists("../data/bids/limited_energy/derivatives/models/preferences_model_no_energy_trace.nc"):
idata = az.from_netcdf("../data/bids/limited_energy/derivatives/models/preferences_model_no_energy_trace.nc")
traces['No_Energy'] = idata
else:
# Fit the model without the energy related preferences:
preference_columns = [
'is_1', 'is_2', 'is_3', 'is_4',
'is_lc', 'is_hc',
'is_trans1', 'is_trans2', 'is_trans3', 'is_trans4',
]
idata = preference_model(beh_data['response'], # Subjects responses
np.squeeze(beh_data[['dv']].to_numpy()), # Optimal decision values
beh_data[preference_columns], # Preferences regressors
subj_idx_raw, subj_labels)
# Add the idata to the rest:
traces['No_Energy'] = idata
# Save the trace to file:
az.to_netcdf(traces['No_Energy'], "../data/bids/limited_energy/derivatives/models/preferences_model_no_energy_trace.nc")Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_intercept, sigma_intercept, beta_planning, sigma_planning, beta_pref, sigma_pref, beta_interaction, sigma_interaction, z_intercept, z_planning, z_biases, z_interaction]Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 667 seconds.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for detailsModel without decision values
In addition, we compared the full preference model with a model without decision values. This is to investigate whether participants behaviour might not rely on any sort of optimal planning but on simpler heuristic based on the structure of the task:
In [5]:
if os.path.exists("../data/bids/limited_energy/derivatives/models/no_planning_model.nc"):
idata = az.from_netcdf("../data/bids/limited_energy/derivatives/models/no_planning_model.nc")
traces['No_Planning'] = idata
else:
# Choice behaviour model with prefences only, no decision values:
pref_regressors = beh_data[[
'is_1', 'is_2', 'is_3', 'is_4',
'is_lc', 'is_hc',
'is_lfc', 'is_hfc',
'e_is_0', 'e_is_1', 'e_is_2', 'e_is_3', 'e_is_4', 'e_is_5', 'e_is_6'
]]
# Create intercept:
intercept = np.ones(beh_data.shape[0])
# Set coordinates:
coords = {
"subject": subj_labels,
"coef_intercept": ["B_intercept"],
"coef_planning": ["B_plan"],
"coef_pref": ["B_" + col for col in pref_regressors.columns],
"coef_interaction": ["slope"],
}
# Model:
with pm.Model(coords=coords) as preference_model:
# Data:
y_obs = pm.Data("y_obs", beh_data['response'])
intercept = pm.Data("intercept", intercept)
preferences = pm.Data("preferences", pref_regressors)
subj_idx = pm.Data("subj_idx", subj_idx_raw.astype("int32"))
# Hyperpriors:
# Intercept term
beta_intercept = pm.Normal("beta_intercept", mu=0, sigma=2, dims="coef_intercept")
sigma_intercept = pm.HalfNormal("sigma_intercept", sigma=2, dims="coef_intercept")
# Preference terms:
beta_pref = pm.Normal("beta_pref", mu=0, sigma=2, dims="coef_pref")
sigma_pref = pm.HalfNormal("sigma_pref", sigma=2, dims="coef_pref")
# Offset parameters:
z_intercept = pm.Normal("z_intercept", 0, 1, dims=("subject", "coef_intercept"))
z_biases = pm.Normal("z_biases", 0, 1, dims=("subject", "coef_pref"))
# Centered parameters:
beta_intercept_sub = pm.Deterministic("beta_intercept_sub", beta_intercept + z_intercept * sigma_intercept,
dims=("subject", "coef_intercept"))
beta_pref_sub = pm.Deterministic("beta_pref_sub", beta_pref + z_biases * sigma_pref,
dims=("subject", "coef_pref"))
# Estimate the score of the bias (i.e. weighted sum of each of the biases regressors):
preference = pm.Deterministic('preference', (beta_pref_sub[subj_idx] * preferences).sum(axis=-1))
# Eta parameter is the weighted sum of the intercept, the bias, the planning values and
# the interaction between the entropy of the bias and the planning
eta = (
beta_intercept_sub[subj_idx, 0] * intercept
+ preference
)
# Expected values:
p = pm.Deterministic("p", pm.math.sigmoid(eta))
# Likelihood
pm.Bernoulli("y", p=p, observed=y_obs)
# Sampling:
traces['No_Planning'] = pm.sample(
draws=n_samples,
tune=n_warmup,
chains=n_chains,
target_accept=0.85,
idata_kwargs={"log_likelihood": True},
)
# Save to file:
az.to_netcdf(traces['No_Planning'], "../data/bids/limited_energy/derivatives/models/no_planning_model.nc")Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_intercept, sigma_intercept, beta_pref, sigma_pref, z_intercept, z_biases]Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 827 seconds.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for detailsModel without interactions
Finally, we also test a model without interaction between preferences entropy and decision values.
In [6]:
if os.path.exists("../data/bids/limited_energy/derivatives/models/no_interaction_model.nc"):
idata = az.from_netcdf("../data/bids/limited_energy/derivatives/models/no_interaction_model.nc")
traces['No_Interaction'] = idata
else:
# Choice behaviour model with prefences only, no decision values:
pref_regressors = beh_data[[
'is_1', 'is_2', 'is_3', 'is_4',
'is_lc', 'is_hc',
'is_lfc', 'is_hfc',
'e_is_0', 'e_is_1', 'e_is_2', 'e_is_3', 'e_is_4', 'e_is_5', 'e_is_6'
]]
# Create intercept:
intercept = np.ones(beh_data.shape[0])
# Set coordinates:
coords = {
"subject": subj_labels,
"coef_intercept": ["B_intercept"],
"coef_planning": ["B_plan"],
"coef_pref": ["B_" + col for col in pref_regressors.columns],
"coef_interaction": ["slope"],
}
# Model:
with pm.Model(coords=coords) as no_interaction_model:
# Data:
y_obs = pm.Data("y_obs", beh_data['response'])
intercept = pm.Data("intercept", intercept)
planning = pm.Data("planning", np.squeeze(beh_data[['dv']].to_numpy()))
preferences = pm.Data("preferences", pref_regressors)
subj_idx = pm.Data("subj_idx", subj_idx_raw.astype("int32"))
# Hyperpriors:
# Intercept term
beta_intercept = pm.Normal("beta_intercept", mu=0, sigma=2, dims="coef_intercept")
sigma_intercept = pm.HalfNormal("sigma_intercept", sigma=2, dims="coef_intercept")
# Planning term:
beta_planning = pm.Normal("beta_planning", mu=0, sigma=2, dims="coef_planning")
sigma_planning = pm.HalfNormal("sigma_planning", sigma=2, dims="coef_planning")
# Preference terms:
beta_pref = pm.Normal("beta_pref", mu=0, sigma=2, dims="coef_pref")
sigma_pref = pm.HalfNormal("sigma_pref", sigma=2, dims="coef_pref")
# Offset parameters:
z_intercept = pm.Normal("z_intercept", 0, 1, dims=("subject", "coef_intercept"))
z_planning = pm.Normal("z_planning", 0, 1, dims=("subject", "coef_planning"))
z_biases = pm.Normal("z_biases", 0, 1, dims=("subject", "coef_pref"))
# Centered parameters:
beta_intercept_sub = pm.Deterministic("beta_intercept_sub", beta_intercept + z_intercept * sigma_intercept,
dims=("subject", "coef_intercept"))
beta_planning_sub = pm.Deterministic("beta_planning_sub", beta_planning + z_planning * sigma_planning,
dims=("subject", "coef_planning"))
beta_pref_sub = pm.Deterministic("beta_pref_sub", beta_pref + z_biases * sigma_pref,
dims=("subject", "coef_pref"))
# Estimate the score of the bias (i.e. weighted sum of each of the biases regressors):
preference = pm.Deterministic('preference', (beta_pref_sub[subj_idx] * preferences).sum(axis=-1))
# Eta parameter is the weighted sum of the intercept, the bias, the planning values and
# the interaction between the entropy of the bias and the planning
eta = (
beta_intercept_sub[subj_idx, 0] * intercept
+ beta_planning_sub[subj_idx, 0] * planning
+ preference
)
# Expected values:
p = pm.Deterministic("p", pm.math.sigmoid(eta))
# Likelihood
pm.Bernoulli("y", p=p, observed=y_obs)
# Sampling:
traces['No_Interaction'] = pm.sample(
draws=n_samples,
tune=n_warmup,
chains=n_chains,
target_accept=0.85,
idata_kwargs={"log_likelihood": True},
)
az.to_netcdf(traces['No_Interaction'], "../data/bids/limited_energy/derivatives/models/no_interaction_model.nc")Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_intercept, sigma_intercept, beta_planning, sigma_planning, beta_pref, sigma_pref, z_intercept, z_planning, z_biases]Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 881 seconds.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for detailsComparing the models:
In [7]:
# Compare the models:
model_comparison = az.compare(traces)
az.plot_compare(model_comparison);
model_comparison| rank | elpd_loo | p_loo | elpd_diff | weight | se | dse | warning | scale | |
|---|---|---|---|---|---|---|---|---|---|
| full_preferences_model | 0 | -1493.538291 | 255.528017 | 0.000000 | 0.691464 | 48.755874 | 0.000000 | True | log |
| No_Interaction | 1 | -1501.438309 | 245.860995 | 7.900018 | 0.061835 | 48.910290 | 5.360603 | True | log |
| No_FC | 2 | -1517.792877 | 227.725070 | 24.254586 | 0.000000 | 48.535449 | 7.563209 | True | log |
| No_CC | 3 | -1539.490753 | 262.803473 | 45.952461 | 0.000000 | 49.889247 | 9.765507 | True | log |
| No_Planning | 4 | -1581.229261 | 217.308042 | 87.690970 | 0.160134 | 48.803948 | 17.317379 | True | log |
| No_Offer | 5 | -1629.835751 | 235.202668 | 136.297460 | 0.045609 | 54.438208 | 19.336254 | True | log |
| No_Energy | 6 | -1636.120850 | 221.734941 | 142.582559 | 0.040958 | 51.521075 | 18.021030 | True | log |